
Built for builders who want to ship real AI
Not for passive learners. This is a doing cohort — you ship something real by Week 12.
PMs transitioning into AI PM roles — building hands-on credibility with working prototypes, not just theory
Mid-to-senior PMs (3–10 years) who want to lead AI initiatives or move to AI-first companies
Engineers, data scientists, and designers pivoting into AI Product Management roles
PMs preparing for AI PM interviews — product sense, metrics, strategy, behavioural, and technical AI questions
Builders who want a structured path through AI fundamentals, RAG, AI agents, evals, and GTM — with a capstone
Anyone who has watched scattered AI tutorials and wants a single, sequenced, mentor-led program
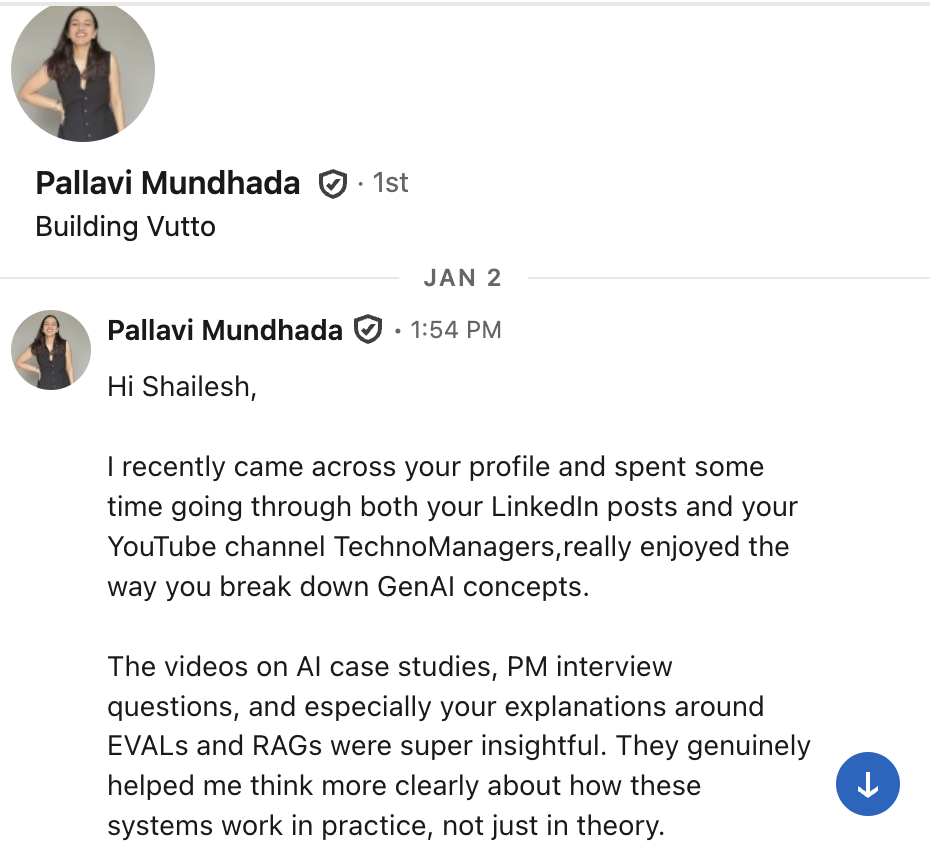
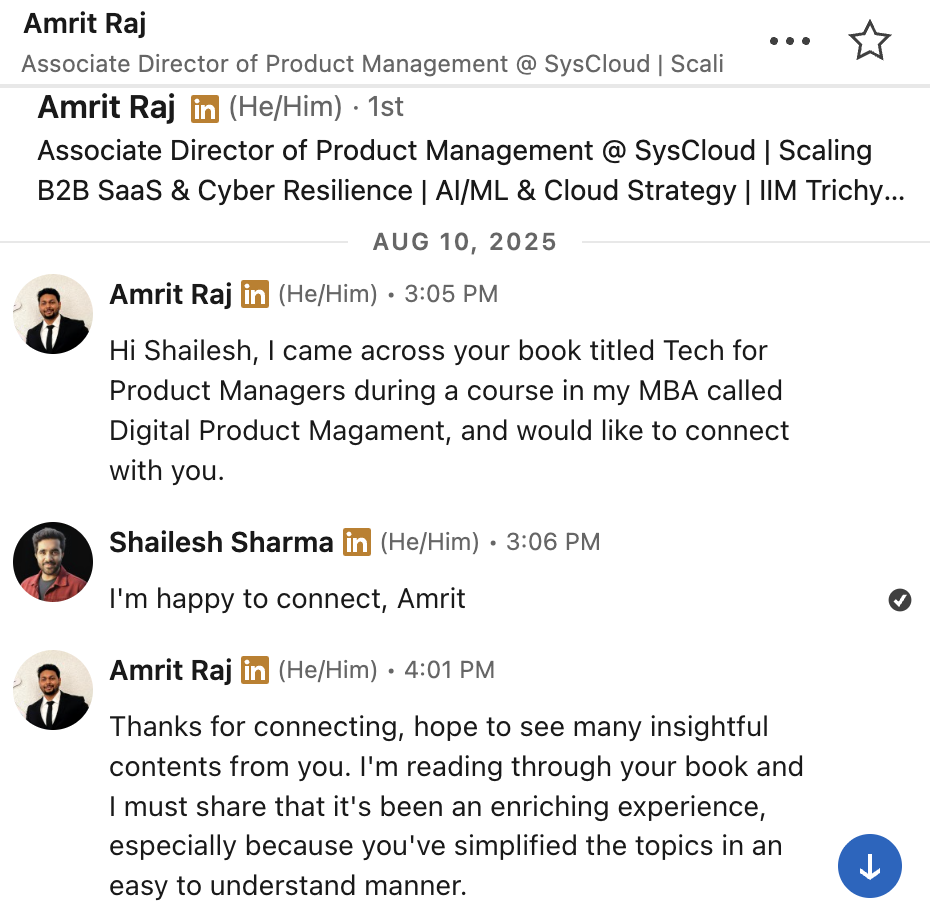
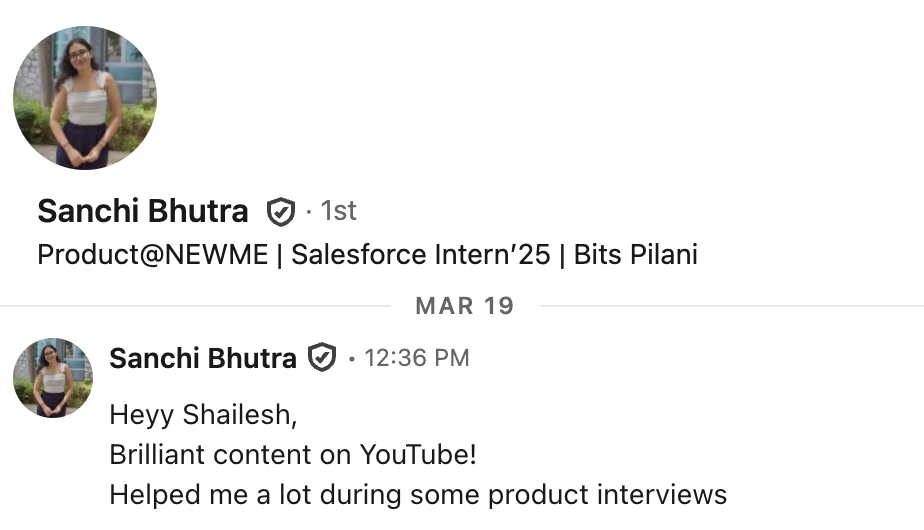
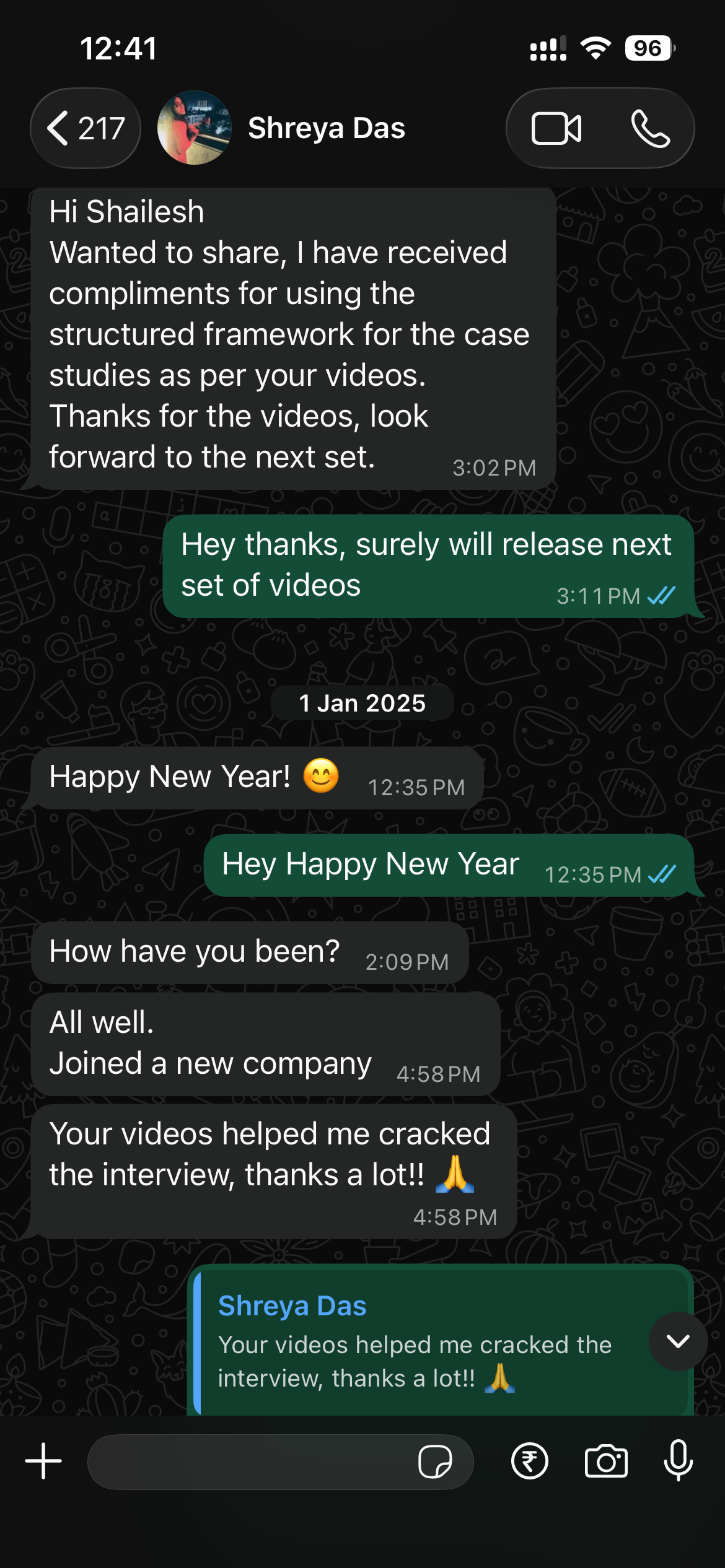
What our students are saying
Real feedback from students who've learned with Shailesh across courses, YouTube, mentorship, and 1:1 coaching.
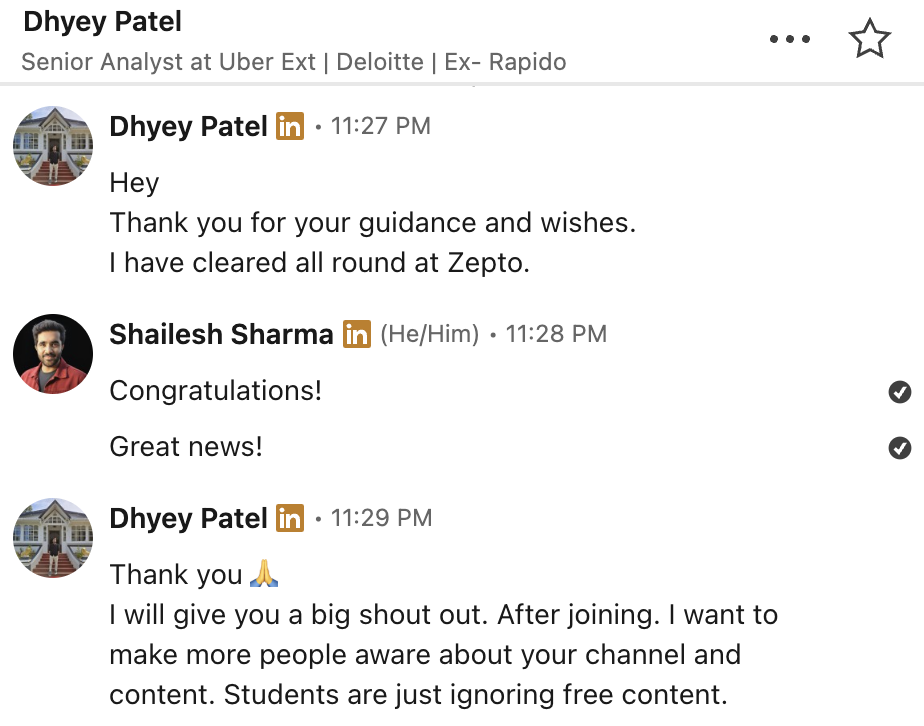
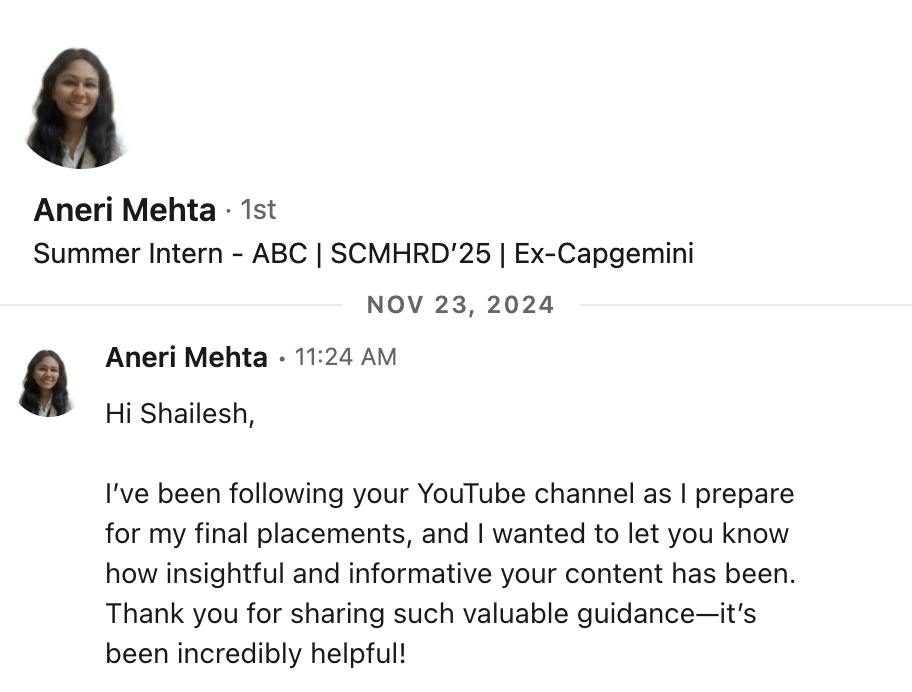
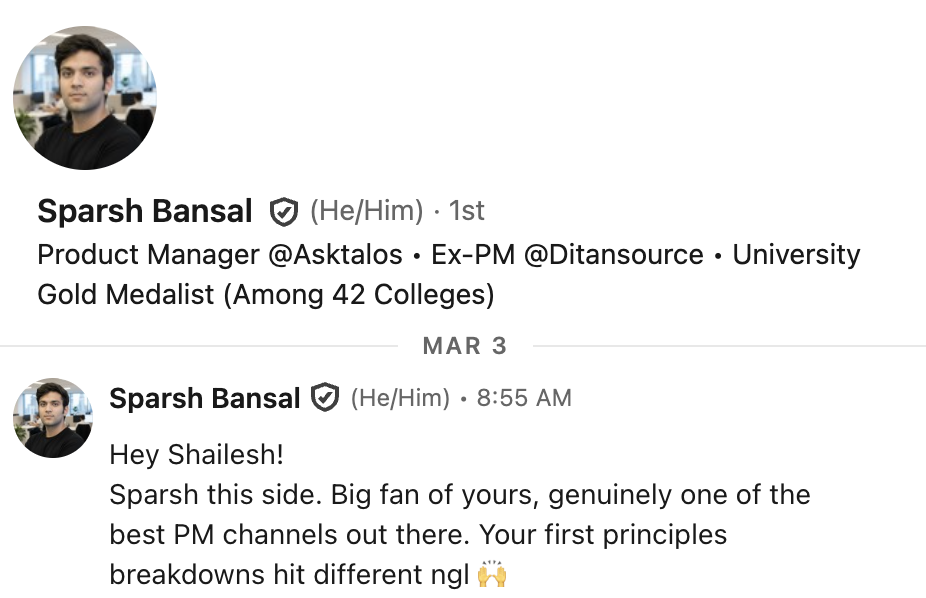
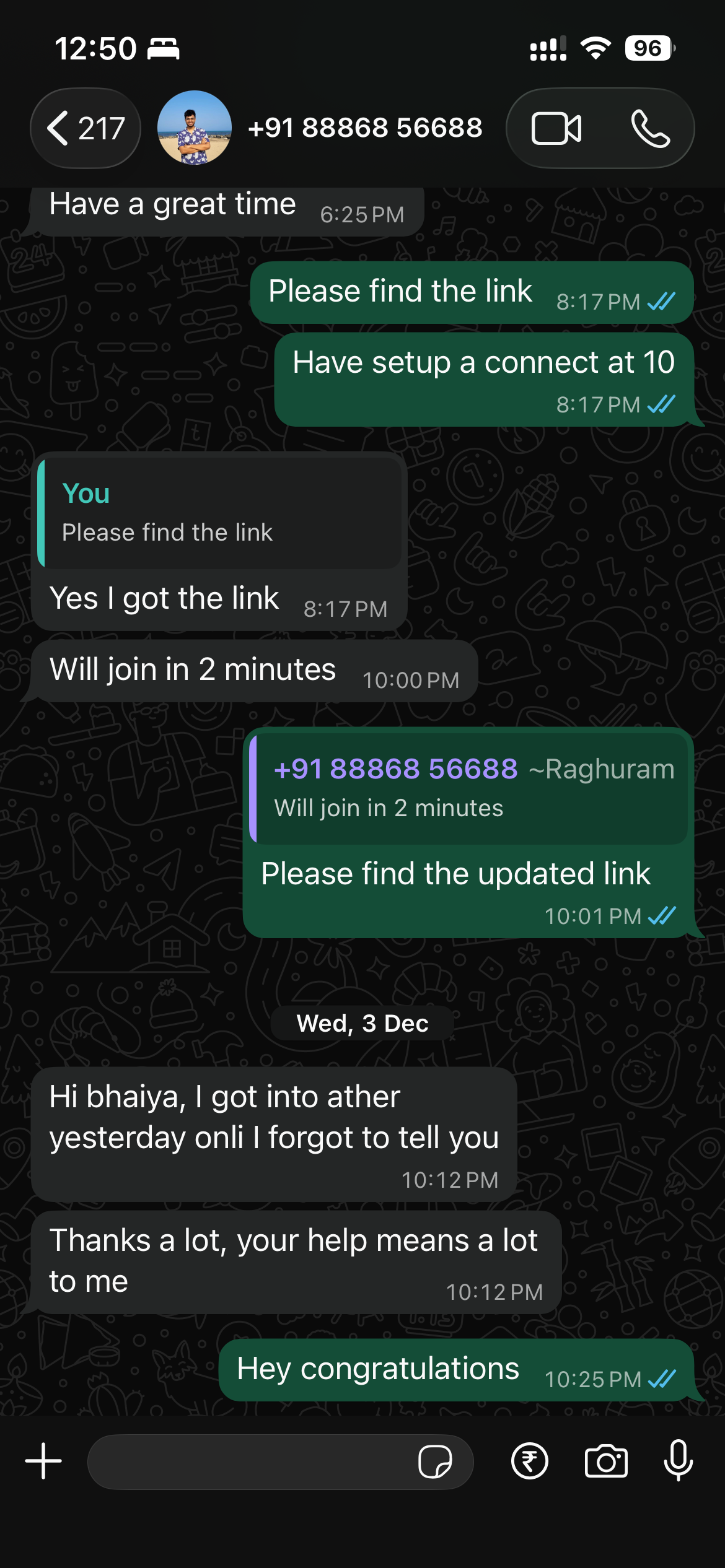
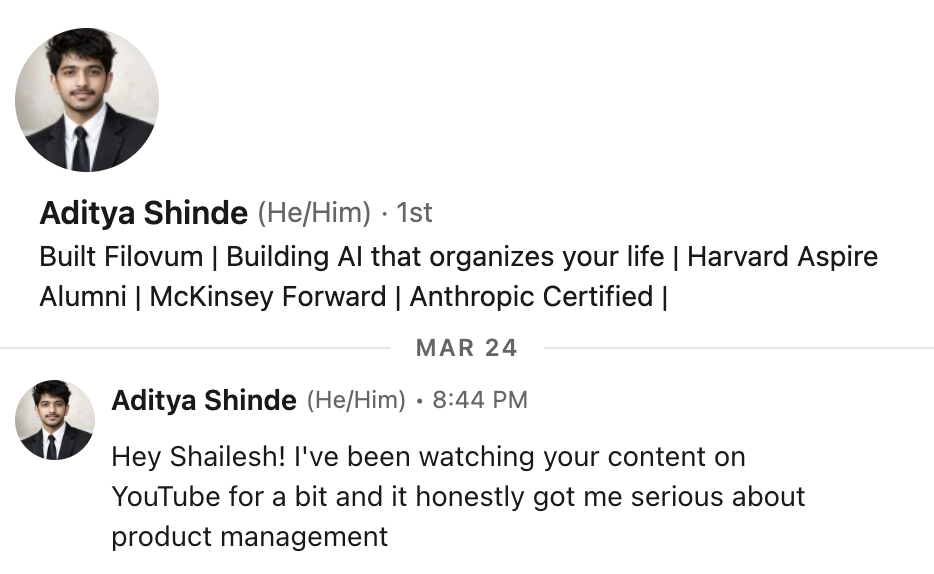
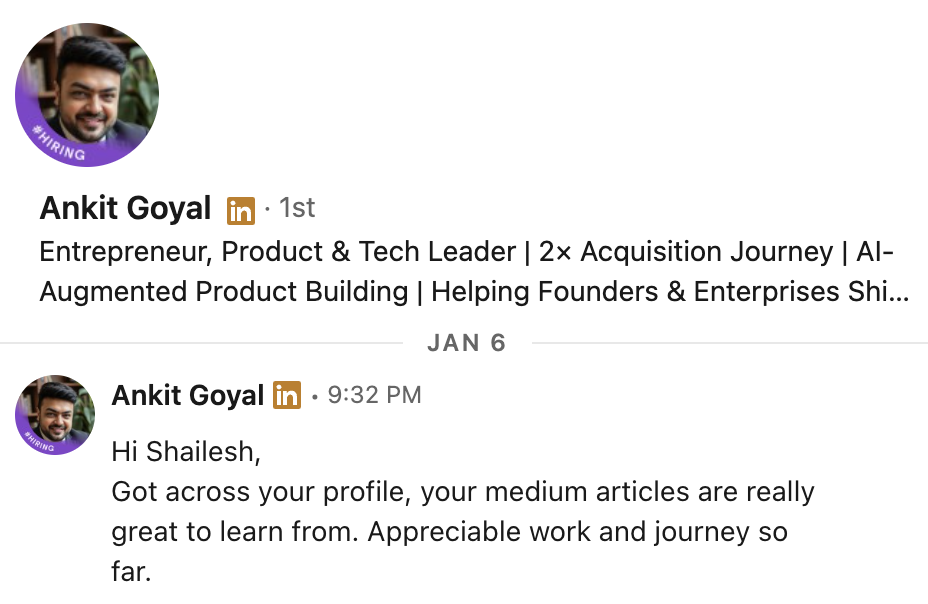
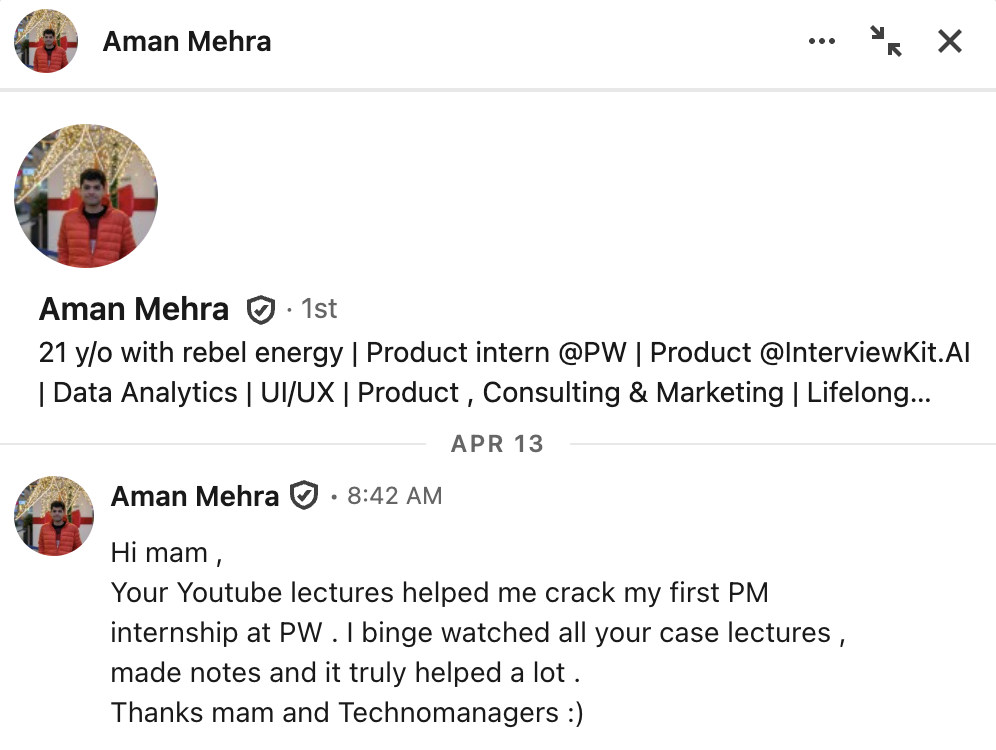
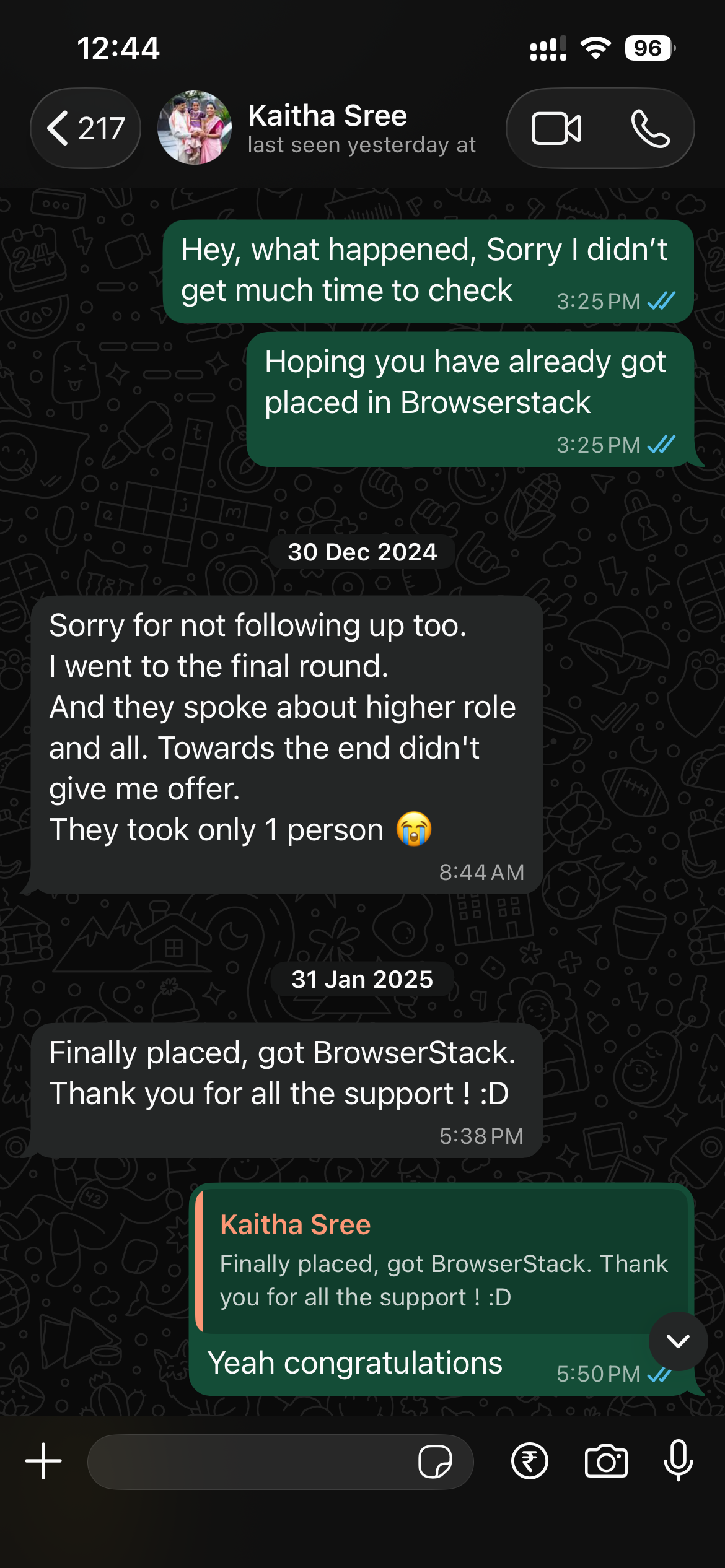
The course teaches you AI PM.
The cohort makes you one.
The self-paced course gives you knowledge. The cohort gives you more knowledge, proof of work, interview readiness, and mentor access — the things that actually get you hired.
| Self-Paced Course | 12-Week Live Cohort Starts Soon |
|
|---|---|---|
| Format | 45 recorded videos, ~7 hrs total | ✓ 45 live sessions, ~90 hrs total |
| Pace | Self-paced, lifetime access | ✓ Structured 12-week schedule |
| Projects you build | 1 prototype demo | ✓ 10+ projects across 12 weeks |
| Capstone product | ✕ | ✓ Full AI product: spec → prototype → evals + Demo Day |
| Hands-on Build Hours | ✕ | ✓ 10 dedicated sessions — RAG, Agents, Evals, UX Audit, Prototyping |
| Mentor feedback | ✕ | ✓ Weekly office hours + scored reviews |
| Interview prep | 20 questions + answers (recorded) | ✓ 10 dedicated sessions (20 hrs) + frameworks to tackle every AI PM question type |
| Mock interviews | ✕ | ✓ 2 full 3-round loops, mentor scored + written feedback |
| Demo Day | ✕ | ✓ Live 8-min presentation + panel Q&A + Best Project awards |
| Strategy & depth classes | ✕ | ✓ GTM, AI Pricing, Model Selection, Latency, AI Safety, AI Analytics, AI ROI |
| SDD + AI Agents + UX | ✕ | ✓ Spec-Driven Development, Agents deep dive (MCP, A2A), UI/UX for AI |
| AI Case Studies (B2C + B2B) | PDF book only | ✓ 4 hrs of live case study discussion with frameworks |
| Tools: N8N, Claude Skills, Lovable | Lovable demo only | ✓ Hands-on with all three + deployment |
| Peer community | ✕ | ✓ Alumni network + job board + accountability partner |
| Best for | Learning AI PM concepts at your own speed | Getting job-ready with proof of work + portfolio |
The course gives you knowledge. The cohort gives you knowledge + proof of work + interview readiness + mentor access.
Week-by-week breakdown
Saturdays + Sundays · 4 sessions/week (10:30 AM–12:30 PM & 2:30–4:30 PM IST) · 8 hrs/week · Weeks 1–10
- Supervised vs Unsupervised Learning — how models learn from labelled vs unlabelled data
- What makes a product 'AI-powered' vs just data-driven
- The AI Flywheel: how user data compounds model quality and moat
- AI product taxonomy: predictive, generative, agentic
- Logistic Regression, Clustering, Decision Trees, SVM, Random Forest, XGBoost
- Match each algorithm to a real PM use case
- Identify the ML technique for your capstone + write algorithm selection rationale
- CIRCLES and STAR frameworks for AI PM interviews
- Clarifying questions: user, metric, constraint, timeline, model constraints
- Build your personal clarifying question bank (10 Qs)
- Q&A on Week 1 concepts + assignment review
- Review AI Opportunity Canvas submissions
- Deep Learning: neurons, backpropagation, transformer architecture
- LLMs: tokenisation, attention, pre-training vs fine-tuning vs RLHF
- Advanced Prompting: CoT, ToT, few-shot, system prompts
- Training vs inference pipelines, batch vs streaming data
- Feature stores, model registries, experiment tracking
- Monitoring: data drift, model degradation, latency vs accuracy tradeoffs
- Evaluating AI features: accuracy, latency, trust, explainability
- Improvement framework: current state → pain points → prioritised solutions
- Answer 2 product sense questions live + write structured improvement pitch
- GenAI Q&A + pipeline review + prompt engineering practice
- Peer review of pipeline maps
- GenAI tool landscape: ChatGPT, Claude, Gemini, Cursor, Midjourney
- AI product stack layers: infra → model → application → UX
- What AI PMs actually do in 2026: scope, skills, cross-functional dynamics
- RAG architecture: retriever + generator + knowledge base
- Vector DBs, embeddings, chunking strategies, retrieval tuning
- RAG vs fine-tuning — PM decision framework
- RCA for AI: segmentation by cohort, device, model version
- Guesstimate frameworks: market sizing, cost estimation
- Solve 2 RCA + 2 guesstimate questions live
- Build a simple RAG prototype using no-code tools
- Connect knowledge base, configure retrieval, test 5 queries
- Peer pairing: test each other's prototypes
- Autonomy levels L1–L4, tool use, memory types (short/long/episodic)
- Planning loops: ReAct, chain-of-agents, reflection patterns
- Multi-agent systems: orchestrator-worker, MCP, A2A
- Real examples: Claude computer use, Copilot agent mode, Devin
- Design the agentic workflow for your capstone
- Prototype using Claude, LangChain, or no-code tools
- Test on 3 scenarios: happy path, edge case, failure
- North Star metric + counter-metrics + guardrail metrics
- 'DAU dropped 20% — walk me through it' execution questions
- OKR setting for AI product teams
- Refine agent based on Sat test results
- Continue MCP & A2A prototyping
- Peer review + mentor feedback on architecture decisions
- Eval types: automated metrics, human evaluation, LLM-as-judge
- BLEU, ROUGE, faithfulness, groundedness, RAGAS for RAG
- Eval pipeline tools: LangSmith, Braintrust, PromptFoo
- Write the eval spec for your capstone AI feature
- Create 10 golden test cases (happy path + edge cases)
- Run manual evals, score results, set launch threshold
- Growth: PLG vs sales-led, AI data network effects
- Pricing: token-based, usage-based, outcome-based, flat subscription
- 'How would you grow Perplexity by 10x?' — answer live
- Review eval specs and golden test sets
- Q&A on eval metrics + troubleshoot scoring issues
- Anatomy of a great spec: context, user stories, constraints, examples, eval criteria
- Vibe coding: prototyping without full engineering support
- Spec-first AI development — the modern PRD-to-shipped handoff
- Write full spec → generate prototype using Claude/AI tools
- Iterate: spec → build → test → revise → rebuild
- Document build process as mini case study
- 'How would you launch a new AI coding assistant?' — end to end
- Structuring GTM: market sizing → beachhead → channels → metrics
- AI-specific GTM: trust, explainability, enterprise procurement
- Continue building on Lovable
- Run eval golden set against prototype
- Mentor office hours for stuck projects
- Designing for non-determinism, trust calibration, streaming + skeleton screens
- HITL patterns: approval flows, correction loops, escalation
- Explainability UX, confidence indicators, anti-patterns
- 8-principle UX audit of your capstone feature
- Redesign error + loading states; write AI UX copy
- Peer UX review, polish prototype based on audit findings
- STAR for AI PM contexts: shipping under uncertainty, data science disagreements
- 'Why AI PM?' — authentic answers
- Start building your 5-story bank
- Hands-on N8N agent building session
- Final prototype refinements + mini case study completion
- Bias types: data, representation, algorithmic, output
- Hallucinations: why LLMs confabulate + PM mitigation strategies
- Regulatory landscape 2026: EU AI Act, India DPDP Act
- AI operational metrics: accuracy, token cost, latency, uptime
- A/B testing AI features: non-determinism + evaluation lag challenges
- Using AI to analyse metrics: SQL + LLM combos
- RAG vs fine-tuning, transformers explained, LLM production risks
- STAR bank: 5 stories + 5 AI general knowledge Qs answered
- Record 'Why AI PM?' and review
- Review risk audits + metrics frameworks
- Peer feedback on dashboards + STAR answer practice
- The agent loop: perceive → plan → act → observe, and where each step breaks
- Tool layer design: schemas, argument validation, idempotency, tool-selection failures
- Memory architecture: short-term context, long-term store, episodic recall
- Control patterns: ReAct vs plan-and-execute vs reflection + stop conditions (max steps, budget caps)
- Wrap your Week 4 agent in a real loop with step limits + token/cost budget
- Add structured tool definitions + input validation; handle a deliberately failing tool call
- Implement retries, fallbacks, and a human-in-the-loop approval gate for high-risk actions
- Add tracing/logging so every step, tool call, and decision is inspectable
- 'Your agent loops forever / burns tokens — how do you fix it?' — loop control & guardrails
- 'How do you make an autonomous agent safe to ship?' — HITL, scoping, reversibility
- Framework: failure mode → detection → mitigation → guardrail; answer 2 questions live
- Full 3-round loop (45–60 min): Product Sense + Metrics + Strategy
- Mentor as interviewer with real-time scoring
- Structured feedback + top 2 improvement areas per round
- Consumer AI product: idea → scale — full post-mortem
- Apply Weeks 1–9 frameworks to analyse each case
- Enterprise AI deployment: procurement, pilot, rollout
- Common success patterns + post-mortems of AI product failures
- Full 3-round loop: Behavioural + Technical AI + Case Study
- Stricter scoring than Round 1, peer interviewer practice
- Compare Round 1 vs Round 2 scores + final readiness assessment
- Group debrief: common mock interview mistakes
- Rewrite weakest 3 answers + finalise 15-answer story bank
- Practice elevator pitch for capstone
- Capstone structure: Problem → User → AI Solution → Stack → Evals → Metrics → Risks → GTM
- Handling 'why not just use ChatGPT?' — peer review with scoring rubric
- Live mock demo: 5 min each + mentor feedback + panel Q&A practice
- Peer feedback on 2 projects + tighten narrative
- Full timed run-through + interview framing of capstone
- Write 2 interview answers using capstone as story
- Last-minute troubleshooting + confidence building
- 8-min capstone presentation + 5-min Q&A from mentor + peer judge panel
- Scoring: problem clarity, solution depth, technical credibility, metrics
- Remaining presentations + Best Project awards
- Speed interview round: 2 Qs per learner in front of cohort
- Portfolio published + LinkedIn launch post
- Certificate awarded + alumni community access
- Async course + job board + accountability partner assigned
Week-by-week deliverable map
Every learner builds toward the same outcome — a portfolio-ready AI product with full spec, prototype, evals, GTM, and live demo.
| Wk | Milestone | What You Deliver | Format |
|---|---|---|---|
| 01 | Problem Definition | AI Opportunity Canvas — problem, user segment, solution gaps, AI angle | Notion doc / 1-pager |
| 02 | Technical Foundation | ML Pipeline Map — algorithm selected, data pipeline, model card | Diagram + rationale |
| 03 | RAG Prototype | RAG design + working prototype: architecture, knowledge base, retrieval strategy | Architecture doc + prototype |
| 04 | Agent Prototype | Agent design + working prototype: autonomy level, tools, memory, HITL, tested on 3 scenarios | Architecture doc + prototype |
| 05 | Eval Framework | Eval spec + 10-case golden set + launch threshold + evals run on prototype | Eval spec + test results |
| 06 | Full Spec + Prototype | Complete spec + polished prototype, mini case study started | Spec doc + prototype link |
| 07 | UX Audit + Polish | 8-principle UX audit, HITL pattern, AI UX copy, prototype finalised, case study complete | UX audit + prototype |
| 08 | Quality & Metrics | Risk audit + responsible AI section + NSM/supporting/guardrail metrics + A/B test plan | Risk doc + metrics |
| 09 | Agent Harness + Mock 1 | Production-grade harness around your agent — loop control + budget caps, validated tool layer, memory, HITL gate, tracing + adversarial test run; Mock Round 1 scored | Harness doc + traces |
| 10 | Interview Ready | 15-answer story bank, 2 mock rounds scored, enterprise case study teardown | Interview doc + case analysis |
| 11 | Presentation Ready | Full capstone deck (10–12 slides) + demo video + mock demo + 2 interview answers | Deck + demo video |
| 12 | 🎤 Demo Day | Live 8-min presentation + portfolio published + LinkedIn post + certificate awarded | Live demo + portfolio |
Every single thing you get
Not a recorded course. Every item below is live, hands-on, and mentor-guided.
What you walk away with
Every output below is built, not watched. You'll have a portfolio to show on Demo Day.
A portfolio-ready AI capstone: problem → spec → prototype → evals → GTM → Demo Day
AI fundamentals mastered — supervised/unsupervised learning, deep learning, LLMs, CoT + ToT prompting
Working RAG system and AI agent prototype with documented architecture and HITL checkpoints
Production-grade evals + an agent harness — golden test sets, RAGAS, LLM-as-judge, loop control, guardrails, and tracing
AI PM strategy depth — model selection, latency, cost-quality tradeoffs, GTM, competitive moats
8 structured Interview Prep modules + 2 full mock rounds with mentor scoring and written feedback
15-answer STAR story bank, polished interview prep doc, capstone framed as interview answers
Live Demo Day — panel Q&A, certificate awarded, portfolio published, LinkedIn launch post
Tools You'll Actually Build With
Not slides. Not demos. You get hands-on with every tool in live sessions — the same stack used by AI PMs and engineers at top companies in 2026.
These aren't picked randomly. Every tool in this cohort maps directly to a real AI PM or engineer workflow you'll encounter in your next role or interview.
Referrals to Top Companies
Shailesh personally mentors each cohort member through the assessment process. For candidates who demonstrate strong preparation and portfolio work, he opens direct referral pathways at companies he's connected with.
Your questions, answered
Ready to Build Your AI Product?
12 weeks. 45 live sessions. Working prototypes. Mock interviews. Live Demo Day. Rolling applications.